

Transformer ≠ Computer
Opening remarks from the inaugural IP Dealmakers AI & EmTech Conference

I’m at the IP Dealmakers AI & EmTech Conference in Austin, TX this week and had the honor of chairing their inaugural AI and emerging technologies conference today. This is a summary of my opening comments.
The transformer is not an incremental advance – it’s a disruptive breakthrough
The transformer, the architecture of which was proposed in 2017, arose out of the research of a small team at Google Brain who published a paper titled “Attention is All You Need.” Few at the time could have predicted that this work would ignite one of the most profound revolutions in computer science since the microprocessor. The architecture it described—the transformer—became the beating heart of today’s foundation models: GPT, Gemini, Claude, LLaMA, and the rest.
But in trying to understand what makes these models tick, I’ve come to an unsettling realization: the transformer breaks the definition of what we call a computer.
If it’s not a computer in the traditional sense, then what exactly is it doing?
It Doesn’t Compute — It Transforms
Unlike a traditional computer, the transformer doesn’t execute code. There’s no program counter, no state transitions, no sequence of instructions leading deterministically from one step to the next. Instead, a transformer is defined by a function:
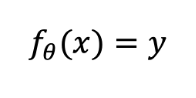
It takes an input vector, passes it through layers of weighted connections, based on the fixed weights —billions of them in GPT-3’s case—and produces an output vector . That’s it.
For a closer look at the details of the transformer architecture, refer to the excellent series by 3Blue1Brown
For reference, GPT-3 has roughly 175 billion parameters, 96 layers, and each token lives in a 12,288-dimensional vector space—its mathematical “universe” of meaning. Nothing is executed in the way we understand code; data just flows through the network, guided by the weights the model learned during training.
A classical computer, by contrast, moves through discrete states. Think of a simple program:

It follows explicit logic—deterministic, sequential, predictable. The transformer doesn’t. It’s probabilistic by design. It doesn’t decide—it predicts.'
Some will argue that the transformer lives inside a mountain of code. And it does. There’s plenty of conventional software around it: code that moves data through memory, orchestrates matrix multiplications across GPUs, loads weights, tokenizes text, and handles batching, caching, and I/O. But here’s the twist: none of that code decides what the model says. It’s just the plumbing. The thinking—if we can call it that—happens entirely inside the frozen geometry of the network’s weights. The surrounding code runs; the transformer predicts.
And yes, it can request that code be run externally. When ChatGPT performs a “web search,” it’s not the transformer firing an HTTP request—it’s external logic responding to a special output token (like <search>), launching a separate process that fetches data and feeds it back as context. The transformer then uses that information—without ever executing a line of code itself. In that sense, it’s a mathematical core suspended in a conventional software shell: deterministic plumbing wrapped around a probabilistic mind.
And all those lines of code the transformer “writes” when you ask it to program? They’re not the result of computation —they’re predicted. The model has seen millions of examples where certain problem descriptions are followed by specific syntax, functions, and variable names. At inference, it samples from that probability space, generating code token by token, guided by patterns it has already learned. The result looks like logic, but it’s imitation—an echo of what real programs do. The code just sits there until classical software takes over to compile, run, or test it. The transformer doesn’t build the program; it imagines it.
The world’s most interesting machine
Here’s an experiment you can try at home to see how strange this really is. Open ChatGPT’s voice interface—the one that runs on GPT-4o, the “omni-modal” model that can handle text, images, and audio. Start a conversation in English. Then, mid-sentence, switch to another language—Spanish, Portuguese, German, Mandarin if you can. Watch what happens.
Nothing happens. It just keeps talking to you.
Instantly, fluidly, with no pause or hint that it’s flipping a switch behind the curtain.
While part of you might imagine it’s detecting which language you’re speaking and loading up a “Spanish module,” that’s not what’s going on at all. There is no language module. The transformer doesn’t store or swap language processors; it represents meaning as patterns of numbers in a shared vector space. Every language—every word, every grammar—lives in that space together. When you switch tongues, you’re not changing the machine’s state; you’re simply feeding it different coordinates. It just knows what to do because the relationships among languages are baked into the same geometry of weights.
What feels like magic is, in fact, mathematics—billions of parameters flexing in sync, predicting the next token without ever deciding which “language” it’s in. It’s simply the world’s most interesting machine.

You Can’t Shrink Your Way to Intelligence
Since Google’s now-famous 2017 paper “Attention Is All You Need,” the game has been scaling—scaling data, models, and compute. That paper introduced the transformer, and everything since has been about pushing its limits. Sam Altman turned the phrase into his own motto—“scaling is all you need”—as OpenAI’s GPT family grew from 117 million parameters in GPT-1 to 1.5 billion in GPT-2, and then to 175 billion in GPT-3, each trained on exponentially larger datasets and GPU clusters.
What’s remarkable is that new capabilities began to appear simply by making the model bigger. Somewhere between a few billion and a few hundred billion parameters, transformers stop behaving like sophisticated autocompletes and start generalizing—reasoning across domains, summarizing, translating, even writing code. Not because they were explicitly programmed to do those things, but because scale, architecture, and data together create a statistical structure rich enough for those abilities to emerge. Scale doesn’t create intelligence—it reveals it. It allows the model’s latent structure to express more of what’s already implicit in the data.
That growth came at a cost. Training these behemoths takes months, megawatts, and mountains of money. GPT-4 reportedly cost tens of millions to train and runs on hardware dense enough to power a small city. The industry is already feeling the limits of “bigger is better.”
That’s why attention has shifted to something subtler: how to make models smarter without making them larger. The new game is specialization. Instead of retraining the entire model, engineers now use techniques like fine-tuning, LoRA (Low-Rank Adaptation), and Retrieval-Augmented Generation (RAG) to adapt foundation models to specific tasks or domains. Each approach trims cost and computation by teaching the model to reuse its general knowledge more efficiently—like giving it a focused graduate degree after a very expensive liberal arts education.
In other words, the transformer era began with brute force. The next wave will be about refinement—figuring out how to extract precision, context, and expertise from systems that were trained to know a little bit about everything.
And yet, amid all this talk of scaling up, a new fashion has taken hold—people claiming to scale down.
This is where the myth of the “proprietary LLM” creeps in. Everyone wants to claim they’ve built their own small, specialized model—as if you can simply shrink a transformer and keep its general intelligence intact. You can’t. The general world knowledge and linguistic nuance that make large models so capable emerge from scale itself. Start pruning too far and you don’t get a leaner genius—you get a forgetful savant. The transformer’s breadth is what gives it depth; strip that away and it stops reasoning, it just recalls.
The Quantum Machine Age
We’ve spent seventy years teaching computers to follow instructions, and in less than ten we’ve built one that doesn’t. The transformer doesn’t execute code—it embodies it. It doesn’t reason step by step; it predicts, infers, and reconfigures meaning in a space we can’t easily map or fully explain. That should feel unsettling. It’s as if computer science has crossed its own event horizon—the boundary between what we can program and what we can no longer fully understand—and found itself in the probabilistic domain physics entered a century ago.
And just as quantum mechanics forced us to rethink what “measurement” and “observation” mean, transformers are forcing us to rethink what “computation” means. We don’t program them—we prompt them. We don’t debug them—we interpret them. We don’t tell them what to do—they show us what they’ve already learned. That’s not an incremental change. It’s the beginning of a new kind of machine intelligence—one that feels less like software and more like discovery.
Really enjoyed the article. Thank you.
Excellent overview and remarks!
"The transformer’s breadth is what gives it depth; strip that away and it stops reasoning, it just recalls." ..."It’s the beginning of a new kind of machine intelligence—one that feels less like software and more like discovery."